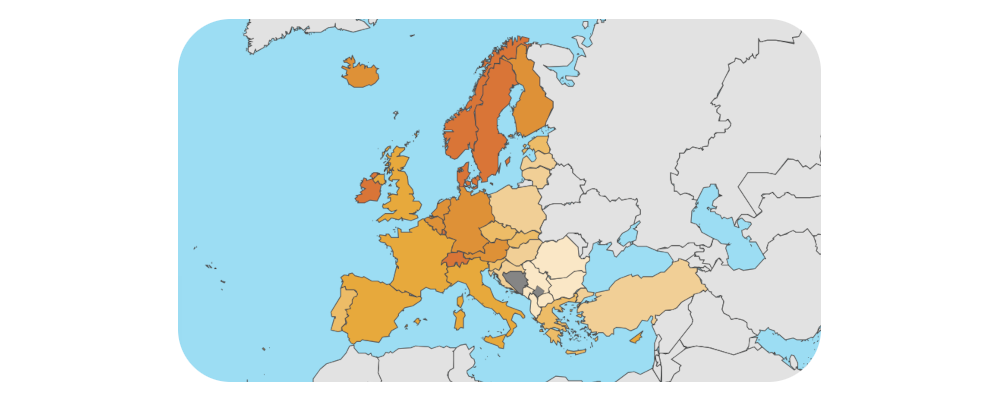
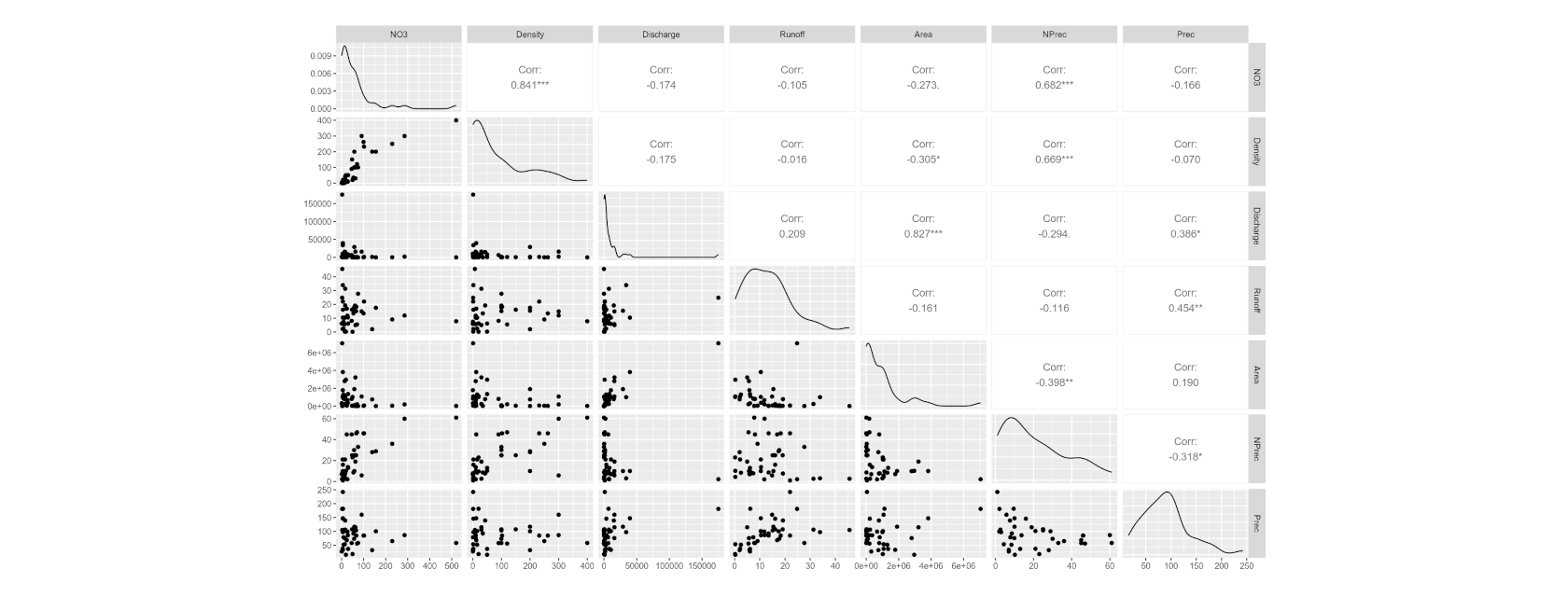
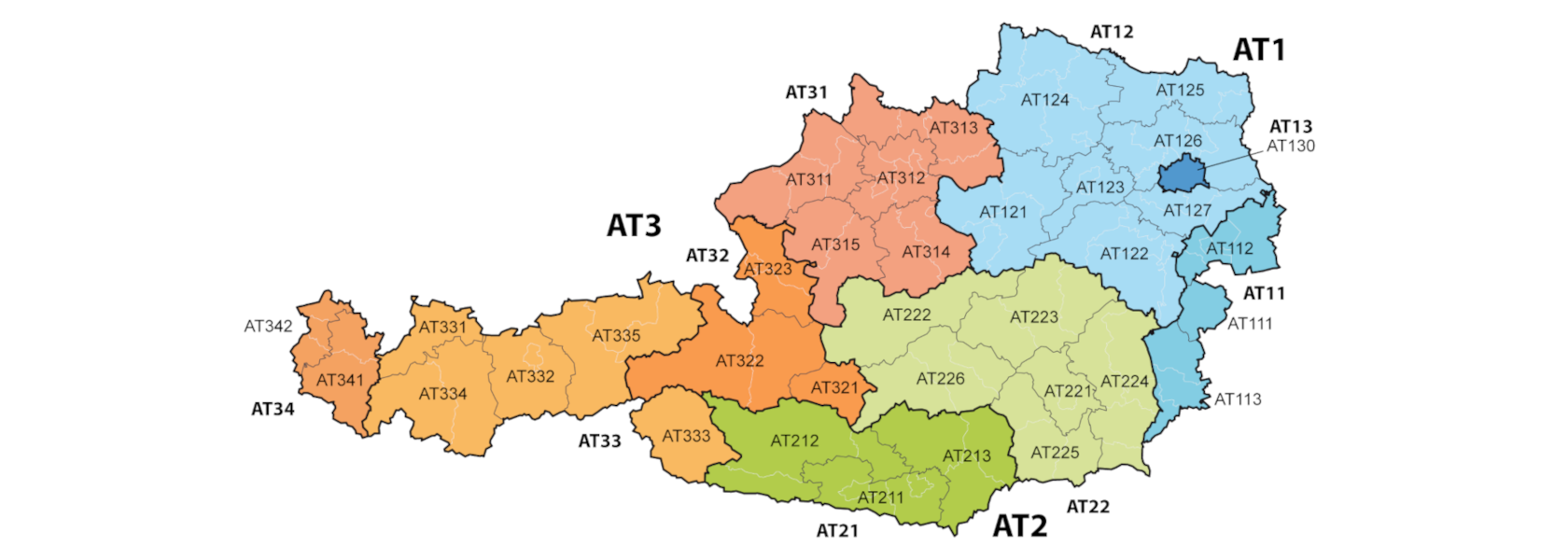
The analysis of the crime data in Austria for the year 2021, focusing on NUTS 3 regions, with the data sourced from Eurostat.
Data Preprocessing We will focus on the Austrian regions according to the NUTS 3 administrative division.
# Load necessary libraries library(eurostat) library(ggplot2) library(psych) id = 'crim_gen_reg' crim_data = get_eurostat(id=id) # Filter for data from the year 2021 data_2021 = subset(crim_data, format(TIME_PERIOD, '%Y') == '2021') # Filter for Austrian NUTS 3 regions at_data = data_2021[grepl('^AT[0-9]{3}$', data_2021$geo), ] df = subset(at_data, select = c(unit, iccs, geo, values)) df = label_eurostat(df) # The subcategories 'Burglary of private residential premises' and # 'Theft of a motorized land vehicle' are already included in 'Burglary' and 'Theft'. # We will exclude them to avoid duplication. df = subset(df, !(iccs %in% c('Burglary of private residential premises', 'Theft of a motorized land vehicle'))) # Separate data into absolute numbers and per 100k inhabitants nr_df = subset(df, df$unit == 'Number', select = c(iccs, geo, values)) pht_df = subset(df, df$unit == 'Per hundred thousand inhabitants', select = c(iccs, geo, values)) # Aggregate data by crime category (iccs) and region (geo) nr_iccs_df = aggregate(list(values = nr_df$values), list(iccs = nr_df$iccs), sum) nr_geo_df = aggregate(list(values = nr_df$values), list(geo = nr_df$geo), sum) pht_iccs_df = aggregate(list(values = pht_df$values), list(iccs = pht_df$iccs), mean) pht_geo_df = aggregate(list(values = pht_df$values), list(geo = pht_df$geo), mean) Initial Data Exploration We will analyze the number of criminal offenses in the regions of Austria according to the NUTS 3 administrative division for the year 2021.
...